Robots协议才是互联网垄断的潜规则
随着百度跟360的搜索引擎拉开了持久战,双方也是从技术、用户体验、市场份额等等各个方面被拉出来做对比,如今Robots协议又被拿来说事儿,有人说360违反Robots协议抓取搜索引擎搜索结果,还有人说着会引起行业大乱,随后似乎又有几个不知名的小网站随声附和。不过反驳之说,似乎只见诸文字,真对360搜索反感的网站倒还真没见到。

Robots协议是什么?在百度百科里的定义,robots协议(也称为爬虫协议、爬虫规则、机器人协议等)也就是robots.txt,网站通过robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。Robots协议是网站国际互联网界通行的道德规范,其目的是保护网站数据和敏感信息、确保用户个人信息和隐私不被侵犯。
当搜索蜘蛛访问站点时,它会首先检查网站根目录下是否存在Robots.txt。如果存在,搜索机器人就会按照robots文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
Robots协议对于小白用户并不重要,之前也并不广为人知。最近和Robots协议相关的新闻都发生在电子商务网站,之前有两个:一个是京东屏蔽一淘的蜘蛛,另一个是淘宝屏蔽百度的蜘蛛。现在,3B大战闹得很凶,很多人把Robots协议拿出来说事儿。
而在我看来,Robots协议充其量是互联网江湖规矩、“潜规则”而已。
Robots协议不是行业标准,只是“搜索引擎的家规”
Google是互联网江湖的大佬,Robots协议的发展恰恰与Google的发展密不可分。
当年,谷歌凭借搜索引擎飞速发展,可很多大型网站原有的商业模式遭到了严重的破坏。为了维护自身的利益,一些欧美大网站联合起来与Google谈判,要求Google必须做到“有所为有所不为”,于是就有了“Robots协议”。
对于这份所谓的Robots协议,很多企业并不买账。毕竟,这只是谷歌自己制定的规范,并不是各大搜索厂商的共识或统一的协议,也从来没有任何一家国内搜索引擎服务商公开承诺遵守Robots协议或签署类似协议或声明。所以,在很多人眼里,充其量是谷歌的“家规”。
而事实上,这个由搜索引擎制定的协议,只会规定如何与网址分享内容,绝对不会对于搜索引擎不利的条款。伴随搜索引擎的发展,Robots协议朝着相反的法相发展:
Robots协议目的是为了限制谷歌,但最终却帮助Google和百度这样的垄断企业遏制了后起的竞争者。因为,Google当年在制定这个协议时,特意留下了后门,即:协议中不仅包括是否允许搜索引擎进行搜索的内容,还包括允许谁和不允许谁进行搜索内容。Google和百度在实现了垄断地位之后,就利用这些排斥性规则挡住了后来的进入者。
这样看来,Robots协议是互联网的一份“不平等条约”“垄断条款”。
值得一提的是,尽管Robots协议造成了搜索引擎的霸权与垄断,但当年制定条款的初衷却非常值得我们尊重。Robot制定的两个原则是:
1、搜索技术应服务于人类,尊重信息提供者的意愿,并维护其隐私权;
2、网站有义务保护其使用者的个人信息和隐私不被侵犯。
现在,我们由Robots协议最初的两个初衷,却得到得到两个与众不同的答案:
抓取搜索页面无罪
既然,Robots协议的初衷是为了保护“信息提供的隐私”“最终信息提供者的意愿”,那么对于在搜索引擎结果中,再次抓取的行为则无罪可言:
搜索引擎的结果被抓取,实质上是经过了两次Robot。那么,如果第一次Robot是完全符合协议,保护了信息者的隐私,那么在已经保护了隐私的搜索结果里,再次检索,又怎能破坏隐私呢?
愿意把信息提供给百度的站长们,无非是希望访问用户增加、网站流量增加。那么,增加一个新的搜索引擎,检索其内容,为其带来更多流量和用户的时候,难道不是最大程度地满足信息提供者的意愿和需求吗?
所以,那些担心百度搜索结果被抓取的人们,或许你们是对百度太没信心了,你们太过于担心百度搜索结果中有“隐私”了!
搜索引擎有资格独占搜索结果么?
那么,百度能否以站长自居也使用Robots协议,拒绝其他搜索引擎的检索呢?显然不能。
对于Robot有人打了个比方:
如果将网站视为酒店里的一个房间,robots.txt就是主人在房间门口悬挂的“请勿打扰”或“欢迎打扫”的提示牌。这个文件告诉来访的搜索引擎哪些房间可以进入和参观,哪些房间因为存放贵重物品,或可能涉及住户及访客的隐私而不对搜索引擎开放。
如果房间代表是每个站长的权利,百度所抓取的内容就是整个酒店,事实上它并也没这个资格,因为搜索引擎是不生产内容的,所以,充其量百度是小区的物业。那么,物业有没有资格在大门口放一块“请勿打扰”的牌子呢?显然不能!因为,它代表不了站长,就像小区物业没法干涉你的好朋友去你家串门一样。
而且,搜索引擎不是制造内容和生产内容的网站,它不是内容的生产者(百度社区产品不在此讨论范围),就像物业一样,它只是一个托管者而已,它无权干扰和干涉它所检索的网站被更多的搜索引擎检索,更无权干涉搜索领域的后起之秀为中小网站带来更多的用户和流量。
所以,那些拿Robots协议说事儿的人们,请想想Robots协议的初衷是什么?是为了保护站长、内容的生产者,而不是保护搜索引擎。而现在,Robots协议已经变成“搜索引擎家规”和行业垄断的潜规则,这些搜索垄断巨头可对流量的垄断和控制力,正让让中小网站岌岌可危。
所以,马海祥博客认为Robots协议最缺的,不是违反设立初衷去保护日益强悍的搜索引擎,而是对搜索引擎自身的制约。而要想最好最大程度地保护站长,只有让更多搜索引擎充分竞争,打破搜索引擎垄断,才能最大程度让利给站长,也是最快和最可行互联网和谐之路。
本文发布于马海祥博客文章,如想转载,请注明原文网址摘自于https://www.mahaixiang.cn/jrht/92.html,注明出处;否则,禁止转载;谢谢配合!



您可能还会对以下这些文章感兴趣!
-
地方网站该如何选择适合自己的运营模式?
运营模式需要考虑盈利模式,但不只是盈利模式。从模式上来看,运营模式又可扩展为:资源型运营模式、服务型运营模式和合作型运营模式。总的来看运营模式的根本是玩转模式资源架构三者关系。也就是说,经营模式就是合理利用自己的资源,确定合理的组织架构,实现盈利模式……【查看全文】
-

回顾2013年度中国互联网十大PK事件
回顾2013年度中国互联网十大PK事件:1、奇虎360和搜狗之争;2、奇虎360和百度之争;3、起点中文网团队与盛大之争;4、小米与魅族的“口水仗”;5、腾讯与阿里的支付战争;6、百度和高德的“地图”战争;7、格力与小米之争;8、网秦与浑水的战争;9、天猫与家居卖场之争……【查看全文】
-

你是否是一名真正合格的SEOer?
最近和一个几年没见的老同学聊天,无意中谈及自己做seo职业的时候,对方很惊讶的问道:原来你就是那些到处在论坛上发广告、博客留垃圾评论、到处发外链的水军呀?当时听到这个评价,确实挺郁闷,也很无语。现在静下心来仔细想想,到底什么才是合格的seoer呢?我们现在的……【查看全文】
-

反思腾讯搜索战略:搜索引擎真的很好做吗?
今年五月,腾讯规模空前的架构调整中,搜索业务受到极大冲击,整个部门被打散,分块合并进其他新成立的事业群之中。此后一个月,腾讯副总裁、搜索业务负责人吴军等高管从任上离职。腾讯在搜索竞争中更换赛道的意愿,已经无需掩饰。 2010年Google中国战略调整之后,腾讯曾被视……【查看全文】
-
360搜索能否成为了中国第二大的搜索引擎
8月22日上午消息,360董事长周鸿掉今日在第二季度财报电话会议上表示,360全站推自主搜索引擎以来,流量增长远远超出预期,这说明中国用户已经被培养了在浏览器和导航站上使用搜索的习惯。 谈及搜索的商业化问题时,周鸿掉表示,目前并不着急加入广告。搜索的商业模式已……【查看全文】
-

腾讯帝国将会如何走向灭亡?
腾讯从马化腾等几个人搞的小软件,到今天的QQ帝国,期间经历了太多的人和事,今天的腾讯被很多人称为中国互联网创业绕不过去的坎。我们也知道,月有阴晴圆缺,百年老店不常有,特别是高科技行业,IBM也衰落了,SGI、SUN完了,互联网的雅虎要关门了,中国第一个上市的互联网公……【查看全文】
阅读:1079关键词: 腾讯 日期:2015-10-31 -

2010年代这10年变化的十大话题
我们总是以为变化会突然降临,但其实所有的变化都酝酿已久。就好像此刻,未来已来,只是你我没有感受到而已。我们以为我们的生活与世界无关,但其实哪怕是远在拉美的一个偶发事件,都将影响着我们的生活。也许是正处于这样一个时代,所以很少有人把2010年代单独拎出来总结一下。相比于1980年代、1990年代,21世纪以来的两个十年其实更加具有区别性。第一个十年是PC时代大繁荣,第二个十年则彻底是属于移动互联网的时代。……【查看全文】
-

微软、苹果和谷歌的产品生态体系
从生态整合的逻辑和市场反馈上看,微软的落后毋庸置疑,虽说目前移动端是三大公司业务高度重合的领域,但从盈利上看,苹果占据了市场的大头,谷歌只是占据了市场的注意力,但要特别说明的是,其实他们各家的整体生态体系(包含移动领域)都相当成熟,只是在移动端这个在……【查看全文】
-

浅谈客户生命周期与品牌定位
客户生命周期是指从一个客户开始对企业进行了解或企业欲对某一客户进行开发开始,直到客户与企业的业务关系完全终止且与之相关的事宜完全处理完毕的这段时间。客户的生命周期是企业产品生命周期的演变,但对商业企业来讲,客户的生命周期比企业某个产品的生命周期重要得……【查看全文】
-

SEO行业发展为什么会这么快遇到瓶颈?
近期在群里看到很多的医疗行业的SEOer在抱怨说,现在的seo太难做了,都在质疑SEO行业未来的发展前景。其实关于SEO发展与瓶颈这个话题在SEO圈内讨论的也已经不是一年两年了,很多SEO界的新人或老人也越来越困惑,在SEO行业内做了这么多年,本人也有很多感触,今天就借助……【查看全文】
-

百度、阿里巴巴、腾讯、新浪、网易、搜狐等互联网公司名称的由来
2016年公布的中国互联网企业排名,BAT、京东、奇虎360、搜狐、网易等巨头位列前10,这些企业的产品几乎每天都在使用,然而,对于这些公司背后的故事,你又知道多少呢?关于马云,马化腾,李彦宏等等,你或许对其公司产品和创业的故事耳熟能详了,那么,你是否知道这些互……【查看全文】
-
微信营销到底好不好?能发展起来吗?
微信是一款通过网络快速发送语音短信、视频、图片和文字,支持多人群聊的手机聊天软件,微信是社会化关系网络,注重点对点的传播,信息到达率几乎是100%,如果你一旦关注了某个公共账号,那么订阅信息的到达率也是100%,这也意味着,你被打扰的概率也是100%……【查看全文】
-

SEO工作岗位会长期存在吗?
SEO可以说是一个新行业,但也很可能会是一个短暂存在的行业。对于SEO的未来,国内外都有争论,因为它关系到成千上万的SEO从业人员,对此我的感觉是比较悲观的,因为SEO太过受制于搜索引擎,多年以后,这种形式的SEO可能已经不复存在了,那SEO未来的发展又将会如何呢?……【查看全文】
-

导致Google+作为社交网络产品失败的原因解析
最新消息:Google+之父维克?冈多特拉从谷歌离职,一位前谷歌工程师则直接宣称Google+作为一个社交网络已经失败。Google+曾自称是有史以来发展最快的社交网络,每月活跃用数量超过3.43亿,超过YouTube和Twitter,但是现在看来好像远远不是这样的。虽然谷歌官方没有宣称Google……【查看全文】
-

腾讯“嘀嘀”和阿里巴巴“快的”争夺市场的商业意图
微信的“嘀嘀”打车和支付宝的“快的”打车两大软件为争夺用户,昨起再投巨额资金打起营销战,乘客下单立返现金,的哥接单积极性更加高涨,在马路边招出租会显得更加不便。今年,“嘀嘀”打车和“快的”打车的补贴规模超过20亿元,背靠腾讯和阿里巴巴,这场“烧钱”之战……【查看全文】
-

浅谈虚拟运营商的商业运作模式
具体的来说,虚拟运营商就是指那些没有基础网络而经营电信或者电信的增值业务的厂商。他们利用基础电信运营商的网络设施或产品,将业务细化、个性化,通过业务代理或者分销等方式向用户提供各种电信增值服务。打一个比方,如果腾讯获得了虚拟运营商的资质,那么我们就有……【查看全文】
-

网络神剧《爱情公寓》是怎么炼成的?
从某种意义上说,《爱情公寓》绝对是一款具有典型意义的文化产品――尽管成本不高,没有大制作与大明星,但却人气火爆,收入自然相当可观。我们先通过一组网络数据来说明《爱情公寓》的火爆吧!2014年1月《爱情公寓》第四季登陆荧屏和网络。首播当天全网点击量达1.5亿次……【查看全文】
-

12306网站所面临的问题真的那么容易解决吗?
今年,12306网站销售火车票已经提前的60天,明天,就开始销售除夕当日火车票了,每到此时,铁路系统唯一的官方购票网站12306就会成为众矢之的,今年也不例外,12306再次被淹没在一片埋怨声中。在网络上也早有人质疑说:如果把12306外包给IBM或者阿里巴巴来做,能否比现在做得……【查看全文】
-

百度、阿里巴巴和腾讯投资布局医疗领域的策略
对于未来的医疗模式,医生的作用不是在移动平台上看病,而是基于线下诊疗已对患者病情有所了解的基础上,结合在线的动态病情监测和远程及时管理,实现在移动平台上为患者提供咨询指导服务,百度医疗大脑将结合百度在大数据领域的经验和技术手段,支持从个人健康管理到大……【查看全文】
-
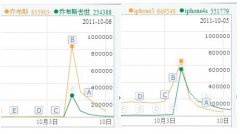
揭秘门户网站如何利用热门专题来截取流量的SEO策略
对于如何提高网站流量,我想这个是站长们永远都讨论不完的一个话题,我也相信站长们都有各自的一直方法去取得流量,比如:选取热门关键词、高指数核心词、论坛推广、qq群发,不过还有一种方法就是截取流量,关于这个如何截取流量,我想大家都会很快的想到很多大型门户网……【查看全文】
分类目录
 2013年百度世界大会概况介绍 首推“轻应用”
2013年百度世界大会概况介绍 首推“轻应用” 从百度内部架构大调整来看百度未来的战略方向
从百度内部架构大调整来看百度未来的战略方向 中小型电子商务公司前期的部门职能分配及运作
中小型电子商务公司前期的部门职能分配及运作 潜在会员加入付费圈子的决定因素是什么?
潜在会员加入付费圈子的决定因素是什么? 如何为自己规划一个自媒体?
如何为自己规划一个自媒体? 如何挖掘产品设计开发的动机和用户需求
如何挖掘产品设计开发的动机和用户需求 APP推广的难点和突破口
APP推广的难点和突破口 产品经理该如何做好产品的架构和流程
产品经理该如何做好产品的架构和流程 资深新闻人写深度报道文章开头的7种写作方法
资深新闻人写深度报道文章开头的7种写作方法 APP在IOS与Android系统界面设计规范
APP在IOS与Android系统界面设计规范 如何通过数据来分析用户与产品的关系
如何通过数据来分析用户与产品的关系 怎样巧妙的运用这些方法写好文章标题
怎样巧妙的运用这些方法写好文章标题互联网更多>>
 百度知道的移动互联网转型
成立十周年的百度知道当之无愧的成为PC端的UGC产品之王,昔年的搜搜问问、奇虎问答、新浪爱问、天涯问答等都成了……
百度知道的移动互联网转型
成立十周年的百度知道当之无愧的成为PC端的UGC产品之王,昔年的搜搜问问、奇虎问答、新浪爱问、天涯问答等都成了……
 百亿级规模的日志系统架构设计及优化
日志数据是最常见的一种海量数据,以拥有大量用户群体的电商平台为例,双11大促活动期间,它们可能每小时的日志……
百亿级规模的日志系统架构设计及优化
日志数据是最常见的一种海量数据,以拥有大量用户群体的电商平台为例,双11大促活动期间,它们可能每小时的日志……
 互联网思维是什么?
“互联网思维”一词有据可查的最早提及者是百度创始人李彦宏,他在2011年首次提到互联网思维,意思是要基于互联……
互联网思维是什么?
“互联网思维”一词有据可查的最早提及者是百度创始人李彦宏,他在2011年首次提到互联网思维,意思是要基于互联……



 空白页面设计的思路
空白页面设计的思路  专业设计师如何设计一个平面banner广告图
专业设计师如何设计一个平面banner广告图  织梦添加文章时出错显示Duplicate entry 'xxx' for key 'PRIMARY'的解决方法
织梦添加文章时出错显示Duplicate entry 'xxx' for key 'PRIMARY'的解决方法 SEO优化 更多>>

|

|
-
 如何提升店铺信誉等级与淘宝刷单技
如何提升店铺信誉等级与淘宝刷单技
在网上一直流传着这样一句话:10个淘宝9个刷,…… -
 小程序与H5路径地址的配置URL适配规则
小程序与H5路径地址的配置URL适配规则
设置URL适配规则,可以使百度搜索得到您的小程…… -
 雅虎搜索引擎的优化技巧及违规作弊
雅虎搜索引擎的优化技巧及违规作弊
其实早在互联网时代来临的时候,雅虎是最流行…… -
 浅谈网站SEO优化的大道理小细节
浅谈网站SEO优化的大道理小细节
很多人在优化网站过程中喜欢扬长避短,只做好…… -
 全面解析用户价值和用户体验之间的
全面解析用户价值和用户体验之间的
用户体验是我们在做SEO过程中强调最多的一个话…… -
 深度解析搜索引擎的原理结构
深度解析搜索引擎的原理结构
对于我们这些做网站优化的来说,如果不懂搜索…… -
 资深运营总监分享淘宝店铺运营的经
资深运营总监分享淘宝店铺运营的经
把淘宝当做一个事业来做,而不是当做一个事来…… -
 地方门户论坛或网站的引流方法技巧
地方门户论坛或网站的引流方法技巧
首先我认为地方性论坛主要引流方法应该来自线……