超链接超文本文档检索系统原理和分析方法
超文本是用超链接的方法,将各种不同空间的文字信息组织在一起的网状文本。超文本更是一种用户界面范式,用以显示文本及与文本之间相关的内容。
一个与根据超链指向的查询索引文档相关,用于检索文档的搜索引擎,它的索引器遍历超文本数据库并寻找包括超链指向的文档地址与每个超链锚文本在内的超文本信息。
超文本信息是贮存在一个倒排索引文件里,这个倒排索引文件亦可用于计算对于各超链指向的特定文档链接向量。输入查询时候,搜索引擎找到锚文本里含有查询词的全部文档向量。与此同时计算了查询向量,然后算出查询向量跟每个文档链接向量的点积。锚文本里含有查询词的全部文档相关点积的加总决定了每一个文档的相关性排名。

本文涉及超文本文档检索,更具体地说是分布在譬如万维网之类的广域网的搜索数据库的超文本文档检索系统和方法。
一、技术背景
随着互联网和网络的流行度增长,查找相关文档的难度越来越大,如果用户找不到第一个感兴趣主题的相关文件,他自然也不会用超链接找到其它的相关文件了。
此外,如果相关文件的作者没有创建其它相关网站的话,单一相关文档的位置可能就无法导向其它文档。因此,信息的增加促进了各种搜索引擎的发展,帮助用户更容易找到所需要的信息。
超文本是个提供一种使用节点与链接处理信息的独特和非连续方法的数据库系统。节点,即文档或文件,包含文本、制图、音频、视频、动画、图像等。而链接使节点或文档与其它节点或文档相连。
最普及的超文本抑或超媒体系统是万维网,它使用超链接使各式各样的节点或文档链接在一起,由此允许以非线性组织网络上的文本。
超链是两个被称为超链头和尾的锚点间的关联。头锚点是目标的节点或文档,而尾锚点是从那个链接而来的文档或节点。
在网络上,超链通常被认定为在尾锚点文档里彰显或凸显的某几个文本或制图。当一名用户览阅尾文档突显的“点击”或“锚文本”质料时,超链自动与用户电脑连接或对那个特定超链“指向”头锚点文档。
当用户已经找到他感兴趣的相关主题的尾部文档时,该超文本系统通常是有效的。
尾部文档的超链接是由文档的作者创建的,他通常已经检查过超链接头部文档的资料了。因此,用户点击超链接的行为,在一定程度上保证了该超链接的头部文档的资料与尾部文档的锚文本之间的相关性。
当一名用户已经找到了尾文档有关的对那个用户感兴趣的标的物,这个超文本系统一般很管用。超链在尾文档被创建来自文档的作者他通常将审视质料在超链的头文档里。因此,一位用户点击一个超链有一个高度数的确认那质料在头文档有一些有关的对锚文本在超链的尾文档里(具体可查看马海祥博客《关于搜索引擎的6大超链接分析算法研究》的相关介绍)。
二、搜索引擎的检索技术
搜索引擎通常把用户查询看作输入,并试图找到与其相关的文件。查询通常表现为几个描述用户感兴趣主题的词。为了确定得到的文档是否与查询匹配,搜索引擎通常把用户的查询看作是文档集合的索引来进行运算。
由于多数的临时用户不喜欢输入过多的文字,及特定的查询更倾向于流行的主题,可能会出现许多与查询不习惯的结果。当搜索引擎已经索引了一个大的文档集合时,比如网络,很有可能会找到大量与查询相关的文档。因此,大多数搜索引擎会列出一张文档的清单,该清单的文档排名由与查询的相关性决定,相关性相对低的文档将不会被识别给用户。
所以,为了限制用户需要浏览的文档的数量并满足用户的信息需求,搜索引擎决定(具有满足用户需求的)文档检索能力的排名的方法极其重要。
几乎所有的搜索引擎排名技术都取决于给出的文档中查询关键词出现的频率,当其它相关因素一样时,关键词在给出的文档中出现的频率越高,该文档的相关分数就越高。
在确定相关分数时,除了词频,也可能会考虑到其它影响因素,如文档频(即包含该关键词的文档数量)。一旦各种因素,如词频或文档频,确定了,例如向量空间模型、概率模型、模糊逻辑模型等的各种模型将会被用来开发数值(具有满足用户需求的)文档检索能力的排名。
比如说,在向量空间模型中,查询关键词qt是查询向量的维度,那用户查询q则是向量。
Q = <qt1, qt2, ..., qtm>
数据库的文档也用关键词表现为向量,关键词dt在文档中则表现为向量维度。
D = <dt1, dt2, ..., dtn>
那么,(具有满足用户需求的)文档检索能力的分数就被计算为Q和D的点积了。
向量Q或D的评估价值会以各种方式进行加权,最为流行的关键词加权公式是:
Weight (t) = TF*IDFt
文档或查询中给出的关键词词频为TF,其反向文档频IDF代替t。反向文档频是指文档集合中包含该关键词的文档的反向数量(具体可查看马海祥博客《如何利用词频统计原理自动提取文章摘要》的相关介绍)。

使用反向文档频以确保如“这”、“的”、“和”等无用词没有高的权重。此外,当查询多重关键词时,如果其中一个关键词出现在许多文档中,使用IDF加权,就会使得含有该关键词的文档获得较低的排名,而含有其它关键词的文档则获得更高的排名。
标准化的关键词加权也会考虑到包含特定关键词的文档的长度。假设在一定量的文本中,关键词出现得越频繁,文档与包含该关键词的查询的相关性就越高。但是,在很多情况下,这个设想是不正确的。
例如,如果查询的是“Java tutorial”,文档J中有100行只含有“Java tutorial”这个词,那J将获得非常高的(具有满足用户需求的)文档检索能力的分数,并被搜索引擎作为相关性最高的文档呈现给用户。
可是,对于用户来说,该文档是无用的,因为它并没有提供任何关于“Java tutorial”的信息。用户真正需要的是一个好的Java程序设计语言指南,像在Java指南网上找到的那样。不幸的是,短语“Java tutorial”并没有在Java指南网上出现100次,因此多数搜索引擎会不正确地认为Java指南网的相关性低,从而获得的(具有满足用户需求的)文档检索能力的排名就低于文档J。
像J这样的文档不会出现在传统的数据库中,因为传统数据库中文档的选取或制作是为了其内容而不是重复某个关键词(具体可查看马海祥博客《搜索引擎自动提取文章关键词原理》的相关介绍)。
网络中,每个人都可以成为发布人,没有人会选择像J这样的文档的。但事实上,为了使自己的文档能被检索到搜索引擎提交的排名表的顶部,有些人会考虑到词频或标准化词频而故意这样构建自己的文档。
比如说,以文本的前五行含有关键词“性”来的方式来设计一个网页,该网站可能会是低质的或是与性无关的,但是搜索引擎却会上当给它一个好的排名,因为网页中关键词“性”出现的频率较高。
在超文本环境中,长度标准化也可能出现问题,如果文档中含有多媒体而不是文本的话,可能会增加精确计算文档相关长度的困难。
传统的搜索引擎使用关键词可能不能检索包含这些关键词的同义词的相关文档。因此,为了查找到包含关键词“attorney”的文档但用户只查询“lawyer”,很多搜索引擎都需要有广泛的同义词词汇,建造这个词库是非常昂贵和困难的。如果相关文档使用的语言与搜索引擎用户输入查询的语言不一样,传统的搜索引擎也不能查找到。翻译工具可以解决这个问题,但是也困难和昂贵。
此外,传统的搜索引擎困难无法识别非文本资料,即使该资料与查询相关。例如,当搜索引擎只能搜索文档中包含关键词“莫扎特”的文本时,一个包含莫扎特图片或音乐示例的网页,可能不会被搜索引擎识别为相关。
三、超文本检索系统概要
索引文档的方法包括获取指向文档的超链接清单,其中每个超链接含有一个或多个关键词。用在指向文档的超链接中的关键词来索引该文档。许多含有特定关键词的超链接,可能会指向同一个文档,用该文档来索引其包含特定关键词的超链接数目。
特定的关键词可能出现在指向许多文档的超链接中,用该关键词索引被含有特定关键词的超链接指向的文档的数目。
索引可能包括创建一个列有每个关键词的文件,含有该关键词的超链接指向的文档的数量,含有该关键词的超链接指向的文档的标识符,和含有指向的被识别文档的关键词的超链接数量。
用含有特定关键词的超链接指向的文档的标识符来索引含有特定关键词超链接指向的文档数量,在指向文档的超链接上的特定关键词的索引可能与被含有特定关键词的超链接指向的反向文档数量一致。
一个关键词可能会在一个指向文档的超链接中出现若干次,用被该超链接指向的文档索引该关键词出现的次数。
关键词可以是词干,本发明中的方法可以在设备中操作,也可以作为可读计算机的指令集储存起来。
依据本发明的另一方面,文档排名的方法是基于文档与查询的(具有满足用户需求的)文档检索能力的,其中查询中至少有一个关键词,而超链接要包含关键词并指向相应的文档。
方法包括将查询的单词比作在一个超链里的单词,为每个超链取得一个(具有满足用户需求的)文档检索能力的排名,包括合计指向特定文档的每个超链接的(具有满足用户需求的)文档检索能力的排名来获取该文档的(具有满足用户需求的)文档检索能力的分数。
查询可以表现为一个查询向量,该向量包含每个关键词的维度。由于每一超链接指向一个文档,该文档可以表现为文档链接向量,该向量包含在指向该文档的相应超链接上的关键词的维度。把查询中的词看作超链接中的词,包含用文档链接向量计算该查询向量的点积。合计指向文档的超链接的(具有满足用户需求的)文档检索能力的排名,包括计算用特定文档的文档链接向量得到的点积来获取该文档的(具有满足用户需求的)文档检索能力的总分,该总分可以被看作是文档获得的排名。
查询向量中的关键词维度可能与被含有该关键词超链接指向的反向文档数量相关。同样地,文档链接向量中的关键词维度与许多被含有该关键词超链接指向的反向文档相关。
超文本文档检索系统和方法的其它固有的特征和优点已经被公开,或对于熟悉这方面技术的人来说,从以下的详细说明及与之对应的附图可以看出其逐渐明显化。
制图简述附图:

优选方案的详细说明:
附图1是包含本发明中超文本检索系统的分散式计算机网络方块图:

附图1是典型的分散式超文本系统,其包括连接着服务器12、13、14、15和16的客户端计算机10。虽然客户端计算机10显示为直接连接服务器12,但它也可以通过服务供应商及一个或多个其它服务器来间接与服务器12连接。服务器13、14、15和16分别包含文档17、18、19、和20里的文件。文件17、18、19和20里的文档对网络用户有效。服务器12包含下面讨论得更详细的索引文件21。为了创建索引文件21,服务器12横贯于整个网络,查找存在于其它服务器13-16中文件17-20的超文本文档。
附图2是索引与检索系统的方块图:

附图2描述本发明的索引与检索系统30的通用结构。系统30外的用户通过用户界面34输入一个查询32,该界面是通常存在于用户的计算机,例如客户端计算机10(图1)。该查询通过网络发送到存在于如服务器12(图1)的服务器上的索引与检索系统30。该系统包括检索引擎36,索引文件38和索引引擎40。以下将会描述检索引擎36和索引引擎40的运行及索引文件38的创建。像在万维网上那样,索引引擎40横贯文档数据库42,创建索引文件38。文档数据库42可能包括文件17-20(图1)。由索引引擎40创建的索引文件38会采取多种方式与本发明一致,可能包括链接文件44,倒排文件46和文档向量文件48,上述的以下都会详细描述到。检索引擎36使用索引文件38以便确定文档的(具有满足用户需求的)文档检索能力的排名,及通过用户界面34在49上输出搜索结果。
附图3是两个超文本文档的方块图:

附图3是文档A和B的超链接以箭头50标出的图解,他们分别是尾部锚点和头部锚点。文档A的地址是URL1,文档B的地址是URL2。地址是以统一资源定位符的形式,它是头部和尾部锚地址的一种统一资源标识符。URL的典型格式是:http://www.mahaixiang.cn/seo/book.html
URL后可以选择性地接着磅符号和字符序列,它被称为片段标识符以便识别文档中的片段,即http://www.mahaixiang.cn/seo/book.html#Chapter1
文档A中包含标题52,摘要54和文本或多媒体56。同样,文档B中包含标题58,摘要60和文本或多媒体62。
文本或多媒体中可能包含像文档A中的锚文本64那样的锚文本。文档A中也包含指令66,它充当着超链接50的指令。表示超链接50中的指令66,显示在超文本标记语言上,它包括指令“href”并确定头部锚点的地址,在这种情况下,文档B的地址为URL2。指令66包含语句“good tutorial on Java”,它识别超链接50的锚文本。通过识别语句“good tutorial on Java”为指令66的锚文本,从而使该语句被突出显示在文档A的文本56中。当强调像文本64这样的文本时,也提醒了文档A的读者超链接的存在。当用户点击锚文本64时,指令66指向文档B,从而引导用户的计算机向地址URL2发送信息,索要文档B的副本。
当然,文档A的作者必须创建指令66并确定锚文本64。通常,按照该作者的看法,创建类似这些文档的作者需要用锚文本的语言(案例中的锚文本64)来描述头部锚文档(案例中的文档B)。因此,如果许多作者像文档A的作者那样用锚文本64做文档B的链接指令,那么查找Java指南的用户非常有可能对文档B中的信息感兴趣。
附图4是包含文件间超链接表示的超文本系统的例子:

附图4是一副简单超文本系统制图,它只包含四个文档,文档A,B,C和D。如附图4所示,该系统只有3条超链接,超链接50(也显示在附图3中),超链接68和70。
如附图3所示,文档A的锚文本“good tutorial on Java”是从文档A到B的超链接的尾部。文档C包含两组锚文本“Java tutorial”和“Sun’s Java site”。文档C的锚文本72通过超链接68指向文档B。锚文本74通过超链接70指向文档D。
附图4所显示超文本系统在下面将被用来描述包括索引引擎、检索引擎和被索引引擎创建的索引文件在内的超文本系统。
附图5是索引编制程序的流程图:

附图5将描述附图2中的索引引擎40的运行。在区块100,索引引擎横贯数据库的每个文档。穿过数据库有多种方法,但通常使用被称为蜘蛛的程序。
蜘蛛开始获取不同的URL地址,发信息到这些地址索要位于它们包含文档。这些地址可以识别服务器,储存在服务器山的文档,和文档组。依靠获得的文档或被URL识别的文档,蜘蛛检验这些文档查找识别其它地址的超链接指令,蜘蛛记录这些地址并寻找地址上的文档。
遍历于区块100的每个文档时,系统也获取区块102相关文档的超链接信息。这样的超链接信息可能包括文档的URL,文档中超链接的锚文本的关键词和含有该锚文本的超链接指向的文档的URL。系统也可能会收集各种各样关于文档的信息,包括它的标题和文档正文。如果有需要的话,系统甚至会创建一个摘要。
在区块104,系统全家一个或多个链接文件,文件的词条的格式是:
<doc.ID, anchor-text>,
其中doc.ID是有相应锚文本的超链接的头部文档的标识符。
doc.ID可能是URL的一种形式,也可能是用文档URL以某种方式来索引的另一种标识符。框104A是链接文件的一个样本,如附图2所提到的,是为文档的数据库而创建的(显示在附图4中)。由于附图4的数据库有3个超链接,就有3个词条在文件104A中。系统可能也储存了关键词在某特定链接的锚文本出现的次数。如例子所示,每个关键词只出现一次在特定的链接中。
虽然附图5显示,穿过区块100的文档比在区块104创建链接文件早,但是有可能一些待创建的链接文件会优先穿过数据库中文档。事实上,一旦数据库被彻底穿过,可能需要更新链接文件和其它穿过文档的索引文件,这是为了确定数据库是否增加了补充文件或者文档是否增加了超链接。
在区块106,不同超链接的锚文本可能被截止了。截词是把词从不同的构形附加成分简化为精简词干的一种方法。在截词时,单词是不分大小写的,如“Tutorial”和“tutorial”是一样的。“Sun’s”被截为“Sun”,“documents”被截为“document”等等。
然后操作方式传递到区块108,它创建一个反文件,所用的词条格式是:
<term, doc.>,
其中term是从超链接的锚文本中摘取的一个词,doc.是该超链接的头部文档的标识符。区块108的反文件显示在文件108A中。由于锚文本“good tutorial on Java”有四个词,则该超链接导致四个词条在文件108A中。
在区块110,反文件以关键词的方式排序,同时计算文档频。文档频被定义为被锚文本中含有特定关键词的超链接指向的文档的数量。例如,附图4中的数据库,关键词“Java”出现在3个超链接的锚文本上,这3个超链接总共指向两个不同的文档。因此,关键词“Java”的文档频是2。关键词“good”只在指向唯一一个文档的超链接上出现一次,那么关键词“good”的文档频率为1。
操作方法其次传递到区块112,创建最终反文件显示在112A中。词条在最终反文件的格式是:
<term, DF, doc1, lf1, doc2, lf2, . . . , doci, LFi>,
其中,term 是锚文本中的关键词,DF是该关键词的文档频,doci是文档i的文档标识符,而LFi则是doci的链接关键词词频。链接关键词词频是指向doci的超链接的数量,其中doci的锚文本是由特定关键词组成。
例如,关键词good在指向文本B的超链接中只出现一次,所以它的链接关键词词频是1。关键词Java出现在指向文档B的两个超链接上,所以其链接关键词词频是2。本发明中,检索引擎的实现得依靠获取与用户查询相关的文档。
doc.id, v1, v2, . . . , vi
<w(t1), w(t2), . . . , w(ti)>
框114中的索引引擎也可能会生成一个文档链接向量,其词条的格式是:doc.id, v1, v2, . . . , vi,其中doc.id是某一特定文档的标识符,vi是链接文件的超链接的向量表示法。每个向量vi的格式表现为1), w(t2), . . . , w(ti)>,其中w(ti)是关键词i在给出的锚文本中表现为向量的超链接的权重。文档链接向量的维度(w(ti))是由TFi *IDF计算的,其中TFi是关键词i的词频,即关键词在给出的锚文本中出现的次数,IDF是关键词的反文档频(1/DF)属于链接向量的特定维度。计算维度时,用文档的总数划分文档频可获得标准化的文档频,使用反向文档频的对数也可以满足需要。
文件114A是文档链接文件的一个例子,它已经生成在区块114中。由于有两超链接指向文档B,则文档B中有两个向量连同其标识符被输入到文件114中。在指向文档B的首个超链接的锚文本中,有四个不同的词“good tutorial on Java ”,那么文档B的首个向量则有四个维度。因为指向文档B的第二个超链接只有两个词(Java,tutorial)在锚文本中,用文档B索引的第二个向量也就只有两个维度。
如下面所描述的,文档链接向量文件114A被用来计算关于特定查询的的(具有满足用户需求的)文档检索能力的分数。不是自动地创建文档链接向量文件,而是在收到查询时再创建文档链接向量文件,这更符合需要。因此,在需要创建的链接向量文件中,唯一的词条与文档有关,这些文档含有查询关键词在指向该文档的超链接的锚文本中。
TF*IDF = 1*1 = 1
在文档B的第一个向量中,前三个维度是“one”,这是因为关键词“good”、“tutorial”和“on”只出现在指向一个文档的锚文本中,并且只出现一次。因此,无论如何,关键词“Java”的词频是1,文档频是2,反文档频是0.5。得出“Java”的TF*IDF是0.5,文档B中首个向量的最后一个维度是0.5,剩下的其它在第二个向量的维度和文档D的向量也是根据TF*IDF的公式计算的。
据附图2显示,链接文件104A、反文件108A、最后的反文件112A和文档链接向量文件114被认为是索引文件。虽然附图5中的文件是首选,但是还有很多索引技术可以和本发明中的系统一起使用的,它们依靠锚文本和链接频来索引文档。例如,可以压缩文件,文件中或文件间可能存在数据的各种关系结构。
附图6是检索过程流程图:

现在引用附图6,检索程序通过向量空间模型和链接向量投票来实现(具有满足用户需求的)文档检索能力的排名。如文件120A所显示的,在框120中,该程序以用户查询的输入为开端。然后,在框122,系统搜索反文件或最后一个反文件,在框124,它用查询关键词找到了所有的文档。如果文档有与其对应的超链接,且超链接的锚文本含有查询关键词,那么该文档有可能与该查询相关。
如框124A所示,系统中有B和D这两个文档,每个文档相对应的超链接的锚文本中都含有一个或多个查询关键词。
再次,在框126进行操作,系统在此可以找到框124A中已被识别的文档的链接向量。文档链接向量与基于文档内容的传统的文档向量形成对照。系统可以简单地通过文件114(附图5)找到文档链接向量,或者可以从反文件和链接文件创建文档链接向量。由于指向文档的每个超链接都与查询相关,框126A可以把文档链接向量连同锚文本一起显示出来。
在框128获取文档链接向量时,系统如框128A所显示那样,也创建了一个查询向量。查询关键词向量维度为TFq*IDF,其中TFq是关键词词频或关键词在查询中出现的次数。IDF是附图5的框110中计算出来的关键词的反文档频。查询中的Java和tutorial的TFq都是1。之前在附图5框110中计算得知,Java的IDF是0.5,tutorial的IDF是1。
一旦找到或计算出查询向量和所有相关文档向量,就可以进行区块130的操作了,即计算每个文档的(具有满足用户需求的)文档检索能力的分数。先通过查询向量计算出文档链接向量,再由此找到每个文档链接向量的点积。向量的点积 <a, b, c> 和 <d, e, f> 被称为。

如果两个向量的维度不同,则每个没有出现在向量中的维度均为0。 例如,文档B的首个向量被说成是:
<1, 1, 1, 0.5>.
在这样的例子中,查询向量将表现为:
<0, 1, 0, 0.5>
所以,每个向量中,代表tutorial的维度和Java的维度相匹配。用文档B的首个文档链接向量来计算,得到查询向量的点积:

同样地,计算文档B的第二个向量得到的点积为1。
框131中,计算特定文档的文档链接向量的点积,可以得到该文档的得票数或总分。文档B的(具有满足用户需求的)文档检索能力的总分是该文档的文档链接向量的点积总和,即1.620。同样的,可以用文档D的唯一文档链接向量来计算查询向量的点积,结果是0.149。
在框132,排序结果显示在框132A中。结果是经过排序的,所以(具有满足用户需求的)文档检索能力的排名总分高的文档排在低的上面。比起列出所有非0的(具有满足用户需求的)文档检索能力的分数,只列出预设的数量更为合适,比如只列出前100个文档,或者只列出(具有满足用户需求的)文档检索能力的分数大于某个数量的文档。
在此描述的程序可以在很多设备上进行操作,包括使用操作系统的Sun Sparc Station。该程序可以当作指令组储存在计算机系统的存储器中。指令组也可以被储存在磁盘之类的电脑可读记忆体中,还可以通过网络发送到另一台计算机。
上述的例子中,没有指向文档A和C的超链接,所以他们的(具有满足用户需求的)文档检索能力的分数都为0,尽管他们都含有查询关键词中的Java和tutorial。
常见的索引和检索引擎可以和基于本发明中的索引和检索系统的超链接组合起来一起使用。在基于链接的(具有满足用户需求的)文档检索能力的分数一样的情况下,可以使用该组合,或仅仅用来补充基于链接的信息。例如,以惯例和(具有满足用户需求的)文档检索能力的排名为基础,假设文档A和C的(具有满足用户需求的)文档检索能力的分数分别为0.6和0.8。利用传统排名的方法去打破基于链接排名的平局,查询的最终(具有满足用户需求的)文档检索能力的排名将会是文档B,文档D,文档C和文档A。
使用组合排名方法的另一个原因是指向文档的超链接太少(如只有一个链接)。在这种情况下,基于一条链接的(具有满足用户需求的)文档检索能力的分数可能并不精确,需要为基于链接的(具有满足用户需求的)文档检索能力的分数设立一个门槛。如果基于链接的(具有满足用户需求的)文档检索能力的分数低于此门槛,就要使用其它的(具有满足用户需求的)文档检索能力的排名方法,或与前者组合起来使用。
因为本发明的索引文件只使用超链接信息,(具有满足用户需求的)文档检索能力的排名并不取决于出现在文档中的词本身,或者,即便与传统的(具有满足用户需求的)文档检索能力的排名结合使用,也不仅仅取决于出现在文档中的词。反而,(具有满足用户需求的)文档检索能力的排名取决于指向文档的超链接的锚文本中的文档描述。文档,譬如上述的文档J,不会获得很高的(具有满足用户需求的)文档检索能力的总分,因为创建该超文本文档的作者并没有把指向文档J的超链接列入文档中。
文档的大小不再是影响(具有满足用户需求的)文档检索能力的排名的因素,因此,避免了关于文档大小的问题。
使用词典 的重要性减少了,这是因为,即使lawyer这个词从不在文档标题“California Immigration Attorneys”中出现,但可能有人创建的指向该文档的超链接的锚文本中含有lawyer这个词。
不能被传统的信息检索方法搜索的图像、图形和音效,如果有指向他们的超链接,就可以被搜索到了。锚文本也可能会以图像、图形等的形式出现,索引引擎可以用诸如尾部文档标题的信息来代替非文字的锚文本。
根据本发明的方法进行索引,用外语创建的文档也可以被检索到。如果用英语写的文档中包含的锚文本指向外语文档,根据本发明,该外语文档将会收到一个(具有满足用户需求的)文档检索能力的分数。
因此,当文档的数据库足够大,如同在万维网,搜索结果是建立在投票的基础上的,投票的决定因素是看别人怎么描述这个文档,而不是该文档的自我描述。从而,上述的例子显示,即使关键词Java tutorial在文档中只出现一次,Sun's Java tutorial网也会获得较高的总(具有满足用户需求的)文档检索能力的排名。
使用基于指向给出文档的超链接的排名方法,用特征词或该领域的描述作为查询来挑选某个领域最新的文档。
前述事项的详细描述只是为了更清晰易懂,不需要理解多余的限制,因为任何的变动对于熟悉这方面的人来说都是显而易见的。
注释:
relevance(相关性) 在信息科学与信息检索圈子中, relevance 表示被检索文档或文档集满足用户的信息需求的程度。relevance 可能包括诸如结果时效性,权威性或新颖性的程度。
node(节点) 即文档或文件,包含文本、制图、音频、视频、动画、图像等。
hypertext(超文本) 是个提供一种使用节点与链接处理信息的独特和非连续方法的数据库系统。
hyperlink(超链) 是两个被称为超链头和尾的锚点间的关联。
马海祥博客点评:
超文本是计算机出现后的产物,它以计算机所储存的大量数据为基础,使得原先的线性文本变成可以通向四面八方的非线性文本,读者可以在任何一个关节点上停下来,进入另一重文本,然后再点击、进入又一重文本,理论上,这个过程是无穷无尽的。从而,原先的单一的文本变成了无限延伸、扩展的超级文本、立体文本。
本文发布于马海祥博客文章,如想转载,请注明原文网址摘自于https://www.mahaixiang.cn/seoyjy/1775.html,注明出处;否则,禁止转载;谢谢配合!上一篇:百度搜索结果标题长度的深入研究解析
下一篇:搜索引擎的分类有哪些?




您可能还会对以下这些文章感兴趣!
-

百度排名算法规则及SEO优化要点总结
做SEO目的其实就是为访客服务,满足用户的需求,想方设法的为了用户提供他们想要看的内容,而不是一味的最求最大利益化,其实百度只是一个展示的平台,只要你有了用户的青睐,你想达到的目标,自然也就水到渠成了,做SEO的核心就是要挖掘用户的力量,只有挖掘用户的力量……【查看全文】
-

Google搜索质量小组专业解答的25个SEO问题
2013年对于众多站长和SEO可以说是最为波折的一年,这一年百度出台了百度绿萝算法、百度石榴算法和百度绿萝算法2.0,而google也相继出台了谷歌EMD算法、熊猫算法、企鹅算法2.0和蜂鸟算法。作为一个站长或SEOer,你是否对这些算法还存在很多的疑惑,尤其对于靠做外贸产品……【查看全文】
-

落地页体验白皮书5.0解读:什么样的顶部嵌入广告符合体验标准
《百度APP移动搜索落地页体验白皮书5.0》对页面广告的内容、形式、位置和面积的要求都做出了详细的说明,受到了全网开发者的广泛关注。关于白皮书5.0中最新提出的顶部嵌入广告标准”落地页首屏顶部允许嵌入不超过一屏面积10%的优质广告”,不少开发者对此提出疑问和反馈,本篇文章将对顶部嵌入优质广告要求做出具体解读:落地页首屏顶部允许嵌入优质广告的总体要求如下:面积:顶部嵌入广告面积必须小于首屏面积的10%。标识:广告位上有明……【查看全文】
-

基于用户投票的六大排名算法研究
随着互联网的发展,网站的数量也在随着成倍的增加着,就中国的互联网来说,根据中国互联网信息中心的数据显示,目前中国的网站数量每半年都会以接近10%的数量增长。这些大量的网站涌现,也就意味着我们已进入了信息大爆炸的时代。 而如今用户担心的已不再是信息太少,而……【查看全文】
-

linux系统或windows+iis系统设置404页面方法
404页面通常是为用户访问了网站上不存在或已删除的页面,服务器返回404错误页面,告诉浏览者其所请求的页面不存在或链接错误,同时引导用户使用网站其他页面而不是关闭窗口离开,消除用户的疑虑。网站设置404页面后,如果网站出现死链接,搜索引擎蜘蛛爬行这类网址……【查看全文】
-

揭秘搜索引擎中的反SEO作弊研究
从搜索引擎优化服务开始,分析了现在所存在的搜索引擎优化的作弊手段;然后提出了四种方法用来预防、破解作弊,并结合现实总结提出逐级分层审查刮度;最后结合Google搜索引擎,讨论并分析了Google搜索引擎的反作弊方法及其中的PR值算法……【查看全文】
-

2011-2012年百度历次大更新数据分析
本篇文章记录了百度从2011年到2012年中旬百度大更新记录的文章。以下数据分析以站长之家官方提供的网站监控分析数据为蓝本,结合优词网等站点观察数据和一些 优秀SEO站长工具和软件的收集,并佐以自己手上二十几个站点作参考进行综合分析,基于统计学分析原理,以大量站……【查看全文】
-

百度快照更新是什么意思?
最近发现有很多刚入SEO行业的新手对网站seo的技巧有很多的误区,比如网站快照不更新就代表网站被惩罚。关于这个观点我们先看看什么是百度快照,百度快照的作用是什么?我们有该如何让百度快照持续更新呢?快照即为Web Cache,可以翻译为网页缓存,当搜索引擎派出蜘蛛去对网站……【查看全文】
-

网站最新SEO优化公式解析
网站seo优化公式 SEO=Clock=C1+L2+K3+O4 1、是一个积分符号,C=content,L=link,K=keywords,O=others。SEO就是一个长期的对时间积分过程,内容是核心; 2、C1丰富的内容是第一位的要素,按照原创、伪原创、转载依次排列内容的重要性满足用户体验; 3、L2链接的合理与……【查看全文】
-

落地页体验白皮书5.0解读:如何合理设置展开全文功能
本文解读文章深度剖析展开全文功能的设置要求。白皮书5.0提到”展开全文的设置必须具有文字标示,且功能实际可用;展开全文功能最多只能出现一次,但不可出现在落地页的首屏内容中(列表页除外);展开全文与广告等引导性内容要设置一定距离间隔,避免干扰用户操作。”如何设置展开全文按钮才更符合用户的体验习惯呢?这篇文章将为你答疑解惑。百度搜索用户研究团队的用户调研发现,搜索用户进入落地页的诉求是浏览页面全部内容,展开……【查看全文】
-

404 Not Found错误页面的解决方法和注意事项
404页面就是当用户访问某网站时,点击了错误的链接时,所返回的页面。最常见的出错提示:404 Not Found。其目的就是告诉浏览者其所请求的页面不存在或链接错误,同时引导用户使用网站其他页面而不是关闭窗口离开。错误页面的文字可以自定义,有些网站没有设置404错误页面,或……【查看全文】
-

如何分析网站是否真的被降权惩罚及解决方法
对于混迹于国内站长圈的朋友来说,每天起早贪黑发外链的网站被百度惩罚似乎在这几年已经是司空见惯的事了,所以很多时候网站流量、排名或者是收录有小幅度波动时,站长都会认为网站又被惩罚了,有到处的去抱怨。其实,很多情况都只是站长自己太过于敏感了而已,网站被百……【查看全文】
-

网站SEO优化的分析诊断报告包含了哪些内容
SEO优化是针对搜索引擎规则做出优化以提高网站排名为目的的优化手段。其所需时间往往是长久性的,包括从网站域名、服务器、程序选取、网站结构、行业分析、竞争分析而切入的优化过程。而SEO诊断,在时间的要求上恰与其截然相反,所求目的完全与优化过程一致:提高网站友……【查看全文】
-
百度最新调整后的算法规则
最近闹得沸沸扬扬的百度6.22和6.28的K站事件到目前已经告一段落了,K站的主要原因已经渐渐明朗,以及百度将会对哪些类型的网站会做降权处理,现在也已经明朗化。针对各大站长漫长的着急等待,以及愤恨的心情,百度目前已经给出了较为明确的答案,那么百度规则和算法调整……【查看全文】
-

反向链接是什么意思
反向链接又叫导入链接(Backlinks),外部链接,是指外部网站有你的网址指向你的网站,其实就是在目标文档(网页)内部进行声明,要求目标文档指向自己(网页)的链接,通俗点讲,网页A上有一个链接指向网页B,则网页A上的链接是网页B的反向链接,换言之,常规链接在文……【查看全文】
阅读:2048关键词: 反向链接 日期:2012-08-14 -

SEO链轮是什么?
SEO链轮(SEO Link Wheels)是从国外引入国内的,一种比较新颖的SEO策略,是一种比较先进的网络营销方式。SEO链轮是指通过在互联网上建立大量的独立站点或是在各大门户网站上开设博客,这些独立站点或是博客群通过单向的、有策略、有计划紧密的链接,并都指向要优化的目标……【查看全文】
-
《百度搜索优质内容指南》全文解读
今日,《百度搜索优质内容指南》在百度搜索学院悄悄地上线了,这是百度近两年,再次重新深度定义什么是百度搜索优质内容,对于SEO人员而言,特别是对于新站长而言,具有非常积极的指导意义,以免造成过多的资源浪费,给予了明确的指导规范的建议。百度搜索2020年全新发布了面向全网内容生产者的《百度搜索优质内容指南》,详细讲述了优质内容的标准,希望给广大内容生产者在生产优质内容时提供参考。关于优质内容的详细标准,请查看以下……【查看全文】
-

百度索引量下降的原因及解决方法
作为一名专业的SEO人员,我们很多的时候都在研究站点中有多少页面可以作为搜索候选结果,也就是一个网站的索引量,所谓网站索引量,就是搜索引擎抓取你网站的数量,这能影响到网站收录率,是一个非常重要的SEO因素,索引量是流量的基础,索引量数据的每一个变动都拨动着……【查看全文】
-
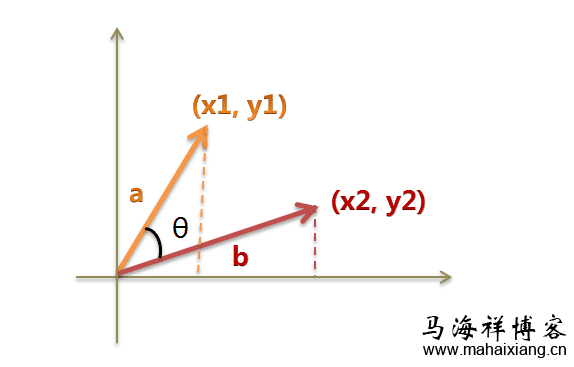
搜索引擎判定相似文章网页的原理
余弦相似性是指通过测量两个向量内积空间的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是 -1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值……【查看全文】
-

百度移动搜索落地页体验白皮书4.0全文解读
进入移动互联网时代,百度搜索致力于提升搜索用户的浏览体验,营造健康的搜索生态。过去一年中,在百度搜索和全网资源提供者的共同努力下,移动搜索落地页广告问题已经得到了明显的改善。现在,百度搜索发布《百度移动搜索落地页体验白皮书4.0》,旨在继续与各内容生产……【查看全文】
分类目录
 百度中文分词技术是什么?
百度中文分词技术是什么? 什么是白帽seo?
什么是白帽seo? 在服务器上设置网站IIS日志的方法步骤
在服务器上设置网站IIS日志的方法步骤 生活中的一些好点子教会你如何赚钱
生活中的一些好点子教会你如何赚钱 O2O营销模式的深入解析
O2O营销模式的深入解析 知乎问答社区的运营机制
知乎问答社区的运营机制 移动设备Web App开发与调试的相关知识要点
移动设备Web App开发与调试的相关知识要点 产品经理该如何做好产品的架构和流程
产品经理该如何做好产品的架构和流程 运营数据中常见的数据陷阱
运营数据中常见的数据陷阱 APP消息推送的误区与真相
APP消息推送的误区与真相 中小站长常用的5种赚钱方法
中小站长常用的5种赚钱方法 传统行业该如何做电子商务?
传统行业该如何做电子商务? 如何撰写一份产品体验报告?
如何撰写一份产品体验报告?互联网更多>>
 基于贝叶斯推断应用原理的过滤垃圾邮件研究
随着电子邮件的应用与普及,垃圾邮件的泛滥也越来越多地受到人们的关注。而目前正确识别垃圾邮件的技术难度非……
基于贝叶斯推断应用原理的过滤垃圾邮件研究
随着电子邮件的应用与普及,垃圾邮件的泛滥也越来越多地受到人们的关注。而目前正确识别垃圾邮件的技术难度非……
 云服务器的常规安全设置及基本安全策略
我们要保障云服务器数据安全,首先应树立正确的安全意识,从监控、入侵防御、数据备份等多方面做好安全措施,……
云服务器的常规安全设置及基本安全策略
我们要保障云服务器数据安全,首先应树立正确的安全意识,从监控、入侵防御、数据备份等多方面做好安全措施,……
 互联网技术的50年发展回顾与分析
1998年至2008年是公认的互联网飞速发展的十年,无论是传输速率、网络规模、关键技术还是应用领域都经历了大幅的增……
互联网技术的50年发展回顾与分析
1998年至2008年是公认的互联网飞速发展的十年,无论是传输速率、网络规模、关键技术还是应用领域都经历了大幅的增……




 织梦dedecms列表页实现无限下拉加载效果的方法技巧
织梦dedecms列表页实现无限下拉加载效果的方法技巧  网站CSS代码优化的7个原则
网站CSS代码优化的7个原则  交互设计的三要素:目标、任务和行为
交互设计的三要素:目标、任务和行为 SEO优化 更多>>

|

|
-
 未来的站内SEO优化需要做些什么?
未来的站内SEO优化需要做些什么?
SEO说难不难,说简单也不是那么简单,很多人问…… -
 医疗行业开展品牌推广急需解决的1
医疗行业开展品牌推广急需解决的1
如今医疗行业要想在互联网上占有一席之地,就…… -
 移动设备前端开发中viewport的理论及使
移动设备前端开发中viewport的理论及使
在移动设备上进行网页的重构或开发,首先得搞…… -
 预约未到诊患者的回访技巧及话术整
预约未到诊患者的回访技巧及话术整
很多朋友问预约是否有技巧,个人认为技巧是沉…… -
 医疗行业该如何做免费营销推广
医疗行业该如何做免费营销推广
当前医疗网站越来越多,竞争也越来越激烈,各…… -
 外贸企业网站常用的5个优化推广方法
外贸企业网站常用的5个优化推广方法
做海外推广不同国内的网站推广,因为在文化、…… -
 百度对站点Logo属性审核原则的具体要
百度对站点Logo属性审核原则的具体要
自百度搜索资源平台后台的站点属性设置开通上…… -
 百度公告:关于近期出现网站劫持用
百度公告:关于近期出现网站劫持用
近日,百度搜索技术团队发现,搜索结果中的部……